Announcing the 0.8.0 Release
This new release introduces support for OpenID Connect (OIDC), data retention policies, monitoring metrics in the console, and more.
Installation
Section titled “Installation”For new installations, see the Installation guide.
For upgrading existing installations, see the associated Upgrading to 0.8.x guide.
OpenID Connect (OIDC)
Section titled “OpenID Connect (OIDC)”OpenID Connect (OIDC) can now be used as authentication provider. This allows you to use your own provider to authenticate users in your organization.
The console also includes a user inactivity timeout, which will automatically log users out after a certain period of inactivity.
The API will now also log the user ID for each request in the logs, which is useful for debugging and auditing. The user ID is taken from the OIDC token,
Head over to the OIDC authentication documentation to learn more.
Data Retention Policies
Section titled “Data Retention Policies”You can now set data retention policies on backups to define how you want to manage your data.
Delete policy
This policy will automatically delete partitions after a certain period of time. This is useful for compliance with data protection regulations, and for cleaning up old data that is no longer needed.
apiVersion: kannika.io/v1alphakind: Backupmetadata: name: delete-data labels: # Mark partitions as expired after 30 days, and remove them. io.kannika/data-retention-policy: Delete io.kannika/data-retention-policy-delete-after: 30dspec: source: "production" sink: "storage"Keep policy
By default, the Keep policy will be used,
which means that data will be kept indefinitely.
apiVersion: kannika.io/v1alphakind: Backupmetadata: name: keep-data labels: io.kannika/data-retention-policy: Keep # Defaultspec: source: "production" sink: "storage"View progress and performance metrics in the console
Section titled “View progress and performance metrics in the console”You can now see the progress of your backups and restores in real-time, and get an overview of the performance of your data operations.
This is the first step towards a more comprehensive monitoring solution, and we will continue to improve and expand the metrics available in the console.
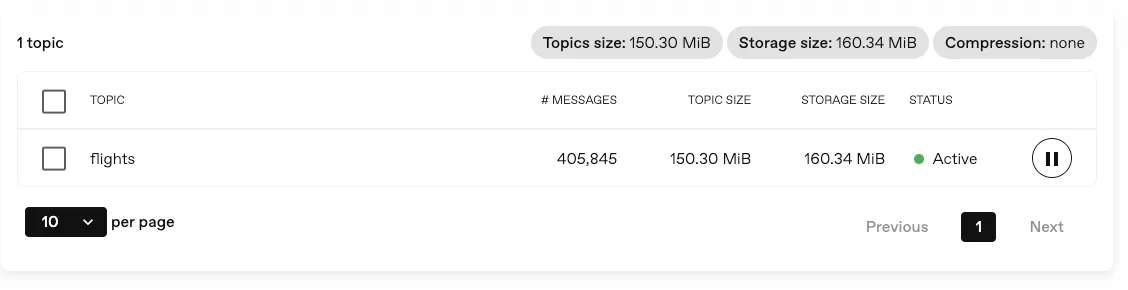
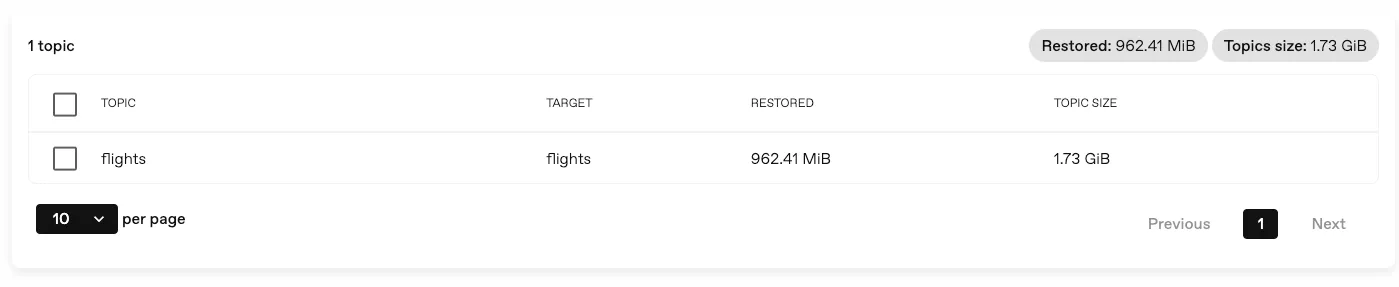
For more information, see the corresponding section.
Persist API data options
Section titled “Persist API data options”The installation process now allows you to configure persistent storage for the API. With the introduction of metrics in the API and the console, the API will now store metrics in its own database.
The following options are available:
emptyDir: The default option, which uses an empty directory in the container. Data is not persisted across container runs.hostPath: Use a directory on the host machine to store the data. This is useful for development and testing.persistentVolume: Use a persistent volume claim to store the data. This is useful for production environments.
Example configuration that uses a persistent volume:
api: storage: persistentVolume: enabled: true storageClass: "default" size: 5Gi accessModes: - ReadWriteOnceSee the API Storage section for more information.
Producer Pool
Section titled “Producer Pool”Before this release, it was only possible to use a single producer to restore data.
This could cause headaches,
as a single producer meant that you could only have one configuration for all topics.
This was especially problematic when restoring data to topics with for example different max.message.bytes settings,
causing the restore to fail in some cases due to the message size being too large for some topics.
To alleviate this issue,
a Restore now has a producer pool which can have a configurable amount of producers.
A Restore will copy the max.message.bytes setting from the broker to create a producer with the correct configuration for each topic.
Topics with the same configuration will share a producer when being restored at the same time.
apiVersion: kannika.io/v1alphakind: Restoremetadata: name: restore-max-producer-sizespec: source: "storage" sink: "production" config: maxProducers: 5 # Use up to 5 producers parallelism: 10 # Restore 10 topics in parallelIn this example, the restore will use up to 5 producers to restore data, shared between the 10 restore tasks. Note that if during the restore there are no producers available with the correct configuration, the task will block until a producer slot becomes available in the pool.
For more information, see the Restore to multiple topics in parallel section.
Restore data within a certain a time window
Section titled “Restore data within a certain a time window”In addition to restoreUntilDateTime,
it is now possible to restore data from a specific timestamp using restoreFromDateTime.
This allows defining a time window for the restore.
Example:
apiVersion: kannika.io/v1alphakind: Restoremetadata: name: restore-timestampspec: source: "storage" sink: "production" config: mapping: orders.v1: target: orders.v2 restoreFromDateTime: "2024-07-02T12:00:00Z" # New restoreUntilDateTime: "2024-08-02T12:00:00Z"See the Restoring data between two dates for more information.
Restore data within an partition offset range
Section titled “Restore data within an partition offset range”It is now possible to define a range of offsets for partitions,
by using the new fromOffset option in addition to untilOffset:
apiVersion: kannika.io/v1alphakind: Restoremetadata: name: restore-offset-rangespec: source: "storage" sink: "production" config: mapping: orders.v1: target: orders.v2 partitions: 0: fromOffset: 100 # New untilOffset: 200In this example, the restore will only restore messages with offsets between 100 and 200 for partition 0.
The untilOffset option for Restores has been made exclusive.
See the Selecting offsets to restore section for more information.
Pod labels
Section titled “Pod labels”Armory will now set the labels io.kannika/backup and io.kannika/restore to the associated Pods of Backups and Restores.
This makes it easier to identify Pods that are part of a specific Backup or Restore.
Bug Fixes
Section titled “Bug Fixes”-
Sink credentials are now correctly set when configuring a Restore via the REST API.
-
When making changes to a Backup and Restore via the console, fields that are not yet supported by the API, were removed from the resource definitions. This includes plugins, schema mapping and restore target configurations. This has been fixed and the fields are now retained.
Performance Improvements
Section titled “Performance Improvements”When restoring data, the broker will return results about the message delivery to the client. Armory uses this data to create a report about the restore process (see Resuming a Restore).
This version of Armory introduces a custom delivery handler that is more efficient than the default handler, which results in a significant performance improvement when restoring a large number of small messages, up to 50% faster in some cases.
The following table shows the improvements made to the restore speed the last few versions when restoring small messages of 32B:
| Version | Time | Speed Up | Message rate | Notes |
|---|---|---|---|---|
| 0.6 | 30.401s | 1 | 329k recs/s | Default allocator |
| 0.7 | 18.519s | 1.64 | 539k recs/s | Replaced allocator with jemalloc |
| 0.8 | 12.105s | 2.51 | 825k recs/s | jemalloc + custom delivery handler |
Other Changes
Section titled “Other Changes”-
Quickly enabling and disabling Backups no longer creates multiple Pods. The operator will wait for pending and terminating pods to finish before creating new ones. The operator uses the
io.kannika/backup-pod-namelabel to track the current running Pod for a Backup. -
The API will now return a proper error message on Kubernetes timeouts.
-
You can no longer configure an API URL when you first visit the console. The console will now automatically use the same URL as the browser, and append
/gqlto it. This URL can be overwritten using theconsole.config.apiUrlHelm value during installation.
Breaking Changes
Section titled “Breaking Changes”- The labels
io.kannika/resource-idandio.kannika/resource-typehave been removed. These labels were remnants of the Endpoints that were removed in 0.7.
Versioned documentation
Section titled “Versioned documentation”Our documentation is finally versioned! You can now select the version of the documentation that matches your installation in the top right corner of the documentation.
Upcoming Features
Section titled “Upcoming Features”Some features that we are working on include:
- Schema Registry Backups: We are going to be adding support for backing up and restoring schemas from a Schema Registry REST API.
- Improved resource management: A more comprehensive resource management solution will be added to the console. This will include being able to update the topic configuration for Backups and Restores, cloning resources, etc.
- WASI plugins: We are working on a new plugin system based on WebAssembly System Interface (WASI). This will allow you to write plugins in any language that can compile to WASI.
Please check the Roadmap for more information on upcoming features.
Release Notes
Section titled “Release Notes”For a full list of changes, see the Changelog.